https://spartacodingclub.kr/hip
스파르타코딩클럽 [힙한 취미 코딩 이벤트]
입장만 해도 경품이? 코딩 무료로 배우고 맥북받자!
spartacodingclub.kr
명절동안 크게 할일도 없고해서 이벤트에 한번 도전해보기로 했다!


1) Pycharm
평소에 Jupyter와 Google-colab만 사용했었지만, 이번에 새로운 강의를 듣게 되면서 Pycharm을 새롭게 사용했다.
https://www.jetbrains.com/pycharm/download/#section=windows
Download PyCharm: Python IDE for Professional Developers by JetBrains
Download the latest version of PyCharm for Windows, macOS or Linux.
www.jetbrains.com
처음 사용하면서 확실히 느꼈던것은 User Interaction 부분에서 상당히 효율이 좋다는 것이었다.

2) selenium, dload, bs4 라이브러리
- 웹 브라우저의 드라이버에 접속하여 제어를 할 수 있게 하는 패키지인 'selenium' 은 보통 웹 테스팅이나 스크래핑 영역에서 자주 사용된다고 한다.

다음 코드와 원하는 브라우저의 URL을 입력하는 것으로 브라우저를 제어할 수 있는 권한을 얻는다.
driver = webdriver.Chrome('chromedriver')
driver.get("https://search.daum.net/search?w=img&nil_search=btn&DA=NTB&enc=utf8&q=%ED%95%9C%ED%9A%A8%EC%A3%BC")
- URL로부터 파일 다운로드를 해주는 패키지인 'dload' 라이브러리도 처음 사용해보았다.
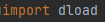
다음 코드를 통해 특정 URL의 이미지를 다운로드 할 수 있다.
dload.save('https://search.pstatic.net/common/?src=http%3A%2F%2Fimgnews.naver.net%2Fimage%2F112%2F2017%2F11%2F18%2F201711181526359647309_20171118152648_01_20171118152847242.jpg&type=a340')
- HTML 및 XML 파일에서 원하는 데이터를 손쉽게 Parsing 할 수 있는 Python 패키지인 'bs4' 중 BeautifulSoup 라이브러리를 통해 원하는 이미지만 다운로드 할 수 있었다.

thumbnails = soup.select("#imgList > div > a > img")
# 선택자를 사용하는 방법 (copy selector)
soup.select('태그명')
soup.select('.클래스명')
soup.select('#아이디명')
soup.select('상위태그명 > 하위태그명 > 하위태그명')
soup.select('상위태그명.클래스명 > 하위태그명.클래스명')
# 태그와 속성값으로 찾는 방법
soup.select('태그명[속성="값"]')
# 한 개만 가져오고 싶은 경우
soup.select_one('위와 동일')
강의 : Sparta 코딩클럽
# 특정 사이트에서 원하는 이미지만 골라서 다운로드
from bs4 import BeautifulSoup
from selenium import webdriver
import time
import dload
driver = webdriver.Chrome('chromedriver')
driver.get("https://search.daum.net/search?w=img&nil_search=btn&DA=NTB&enc=utf8&q=%ED%95%9C%ED%9A%A8%EC%A3%BC") # 여기에 URL을 넣어주세요
time.sleep(5)
req = driver.page_source
soup = BeautifulSoup(req, 'html.parser')
###################################
thumbnails = soup.select("#imgList > div > a > img")
i=1
for thumbnail in thumbnails:
src = thumbnail["src"]
dload.save(src, f'Imgs_homework/{i}.jpg')
i+=1
###################################
driver.quit() # 끝나면 닫아주기'All Development' 카테고리의 다른 글
| Python) 힙한취미코딩 - 워드클라우드(WordCloud) (1) | 2021.09.17 |
|---|---|
| Python) 힙한취미코딩 - 크롤링(Crawling) (0) | 2021.09.16 |
| 백준 12865번) 평범한 배낭 (Python, C#) (0) | 2021.05.19 |
| 백준 15652번) N과 M(4) (Python) (0) | 2021.05.12 |
| 백준 18870번) 좌표 압축 (Python) (3) | 2021.05.11 |